爬取 bilibili 用户头像、用户名、uid
1、前言
今天朋友突然找我,说需要我爬取一下 bilibili 一个范围内的 头像 和 用户名 。所以我也就研究了一下 Python 的爬虫并且稍微看了一下 bilibili 的用户数据获取。
2、查找头像、用户名、uid的数据位置
首先我研究了一下 bilibili 的页面,发现并不是一个静态页面 (废话),所以肯定不能使用之前爬取 笔趣阁 的方式爬取。
当然,如果你执意要爬取个人主页的页面的话,你只能获得这个报错
我们通过 Chrome 的 F12 中 网络 的抓包数据来看
有太多数据了,我们利用搜索来寻找包位置
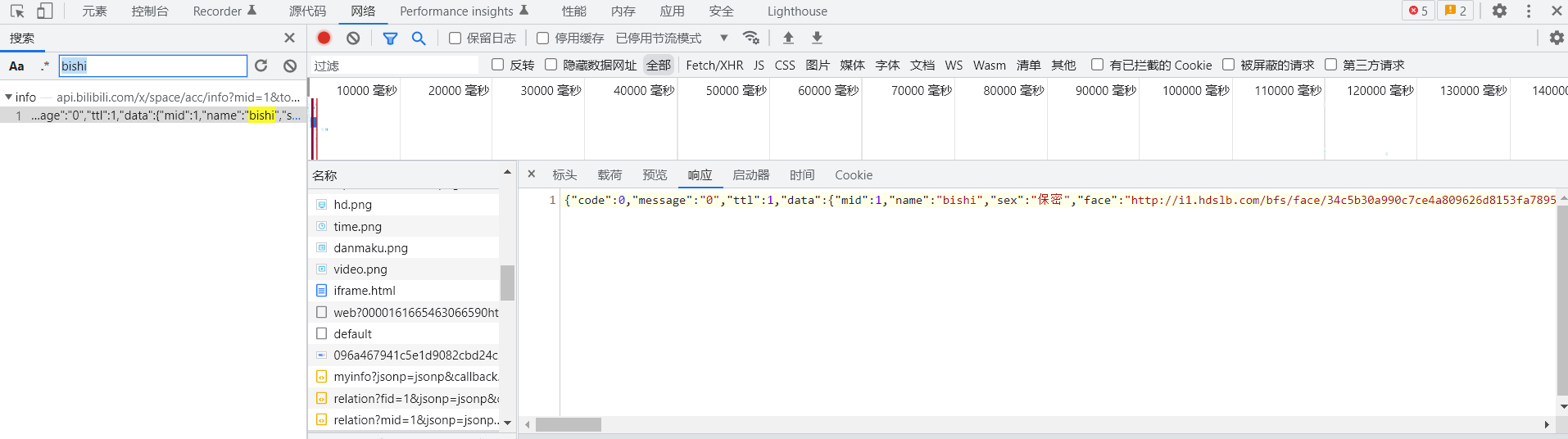
我们看看这个数据包的标头
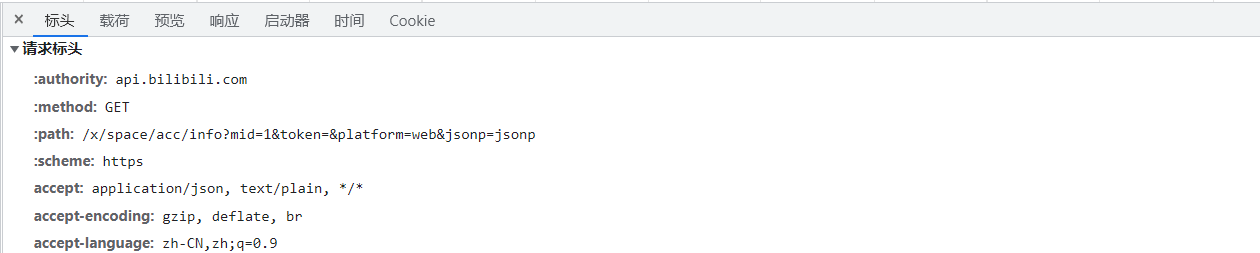
根据标头我们得知
-
使用了
https协议 -
GET获取方法 -
域名是
api.bilibili.com -
path 是
/x/space/acc/info?mid=1&token=&platform=web&jsonp=jsonp\
其中这个 mid 应该就是用户的uid。
我们得知了我们所需要的信息,打开 Python 开始写请求
3、Python 编写
所以我们先导入
-
requests
-
os
-
random(可选)
-
time(可选)
后面两个可选主要是为防止爬虫爬取过快导致被判定为恶意ip然后被ban掉
先确定Host https://api.bilibili.com
然后将用户的浏览器头导入
声明并赋值一个变量,用来切换 Uid
host = "https://api.bilibili.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
id = 1拼接一下获得完整的 Url
hostPath = "/x/space/acc/info?mid=" + str(id) + "&token=&platform=web&jsonp=jsonp"
url = host + hostpath然后发送请求头并保存响应体
requestsPersonalData = requests.get(url, headers=headers)通过输出响应体,我们发现用户的数据在 Data 列表中
那么我们就获取响应体中的 Data 数据
因为获取的响应体是字典模式,所以我们需要使用获取字典的方法获取我们需要的数据
requestsData = requestsPersonalData.json().get('data')然后将我们需要的数据都赋值到变量中
name = requestsData.get('name')
level = requestsData.get('level')
faceImgUrl = requestsData.get('face')
uid = requestsData.get('mid')接着我们发现头像并不是返回图片,而是返回一个头像的 Url。那么我们就再次从 Url中获取头像
faceImg = requests.get(faceImgUrl, headers=headers)然后设定好保存的路径
writePath = str(level) + "/" + name + "-" + str(uid) + ".jpg"将爬取到的数据以等级区分,将头像保存到文件,文件名以 用户名-Uid 的形式保存
先判断是否有这个等级的文件夹,如果没有则创建
if not os.path.exists(str(level)):
os.mkdir(str(level))接着判定是否存在同名的文件,如果不存在则将结果保存
if not os.path.exists(writePath):
with open(str(writePath), "wb") as f:
f.write(faceImg.content)
f.close()
print("写入" + str(uid) + "完成")这样我们就实现了爬取一个用户的数据,我们将循环加上
host = "https://api.bilibili.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
id = 1
while id < 900000:
hostpath = "/x/space/acc/info?mid=" + str(id) + "&token=&platform=web&jsonp=jsonp"
url = host + hostpath
requestsPersonalData = requests.get(url, headers=headers)
requestsData = requestsPersonalData.json().get('data')
name = requestsData.get('name')
level = requestsData.get('level')
faceImgUrl = requestsData.get('face')
uid = requestsData.get('mid')
faceImg = requests.get(faceImgUrl, headers=headers)
writePath = str(level) + "/" + name + "-" + str(uid) + ".jpg"
if not os.path.exists(str(level)):
os.mkdir(str(level))
if not os.path.exists(writePath):
with open(str(writePath), "wb") as f:
f.write(faceImg.content)
f.close()
print("写入" + str(uid) + "完成")
id = id + 1然后添加一个2-8秒的随机延迟
host = "https://api.bilibili.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
id = 1
while id < 900000:
hostpath = "/x/space/acc/info?mid=" + str(id) + "&token=&platform=web&jsonp=jsonp"
url = host + hostpath
delayTime = random.randint(2, 8)
time.sleep(delayTime)
requestsPersonalData = requests.get(url, headers=headers)
requestsData = requestsPersonalData.json().get('data')
name = requestsData.get('name')
level = requestsData.get('level')
faceImgUrl = requestsData.get('face')
uid = requestsData.get('mid')
faceImg = requests.get(faceImgUrl, headers=headers)
writePath = str(level) + "/" + name + "-" + str(uid) + ".jpg"
if not os.path.exists(str(level)):
os.mkdir(str(level))
if not os.path.exists(writePath):
with open(str(writePath), "wb") as f:
f.write(faceImg.content)
f.close()
print("写入" + str(uid) + "完成")
id = id + 1这样爬取 bilibili 的用户名、头像、等级的爬虫就完成了